
Le pooling est utilisé dans les CNN pour faciliter la reconnaissance de features, quelque soit leur position/orientation dans l’image. On recherche la“local translation invariance.”
Pooling layers provide an approach to down sampling feature maps by summarizing the presence of features in patches of the feature map. Two common pooling methods are average pooling and max pooling that summarize the average presence of a feature and the most activated presence of a feature respectively.
A Gentle Introduction to Pooling Layers for Convolutional Neural Networks
La meilleure explication du pooling est celle d’Aurélien Geron :
Figure 14-8 shows a max pooling layer, which is the most common type of pooling layer. In this example, we use a 2 × 2 _pooling kernel_9, with a stride of 2, and no padding. Only the max input value in each receptive field makes it to the next layer, while the other inputs are dropped. For example, in the lower left receptive field in Figure 14-8, the input values are 1, 5, 3, 2, so only the max value, 5, is propagated to the next layer. Because of the stride of 2, the output image has half the height and half the width of the input image (rounded down since we use no padding).
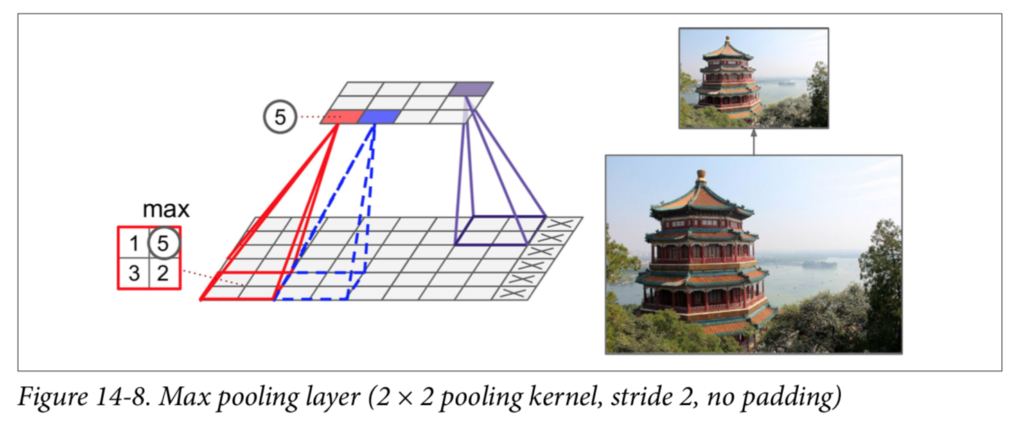
Other than reducing computations, memory usage and the number of parameters, a max pooling layer also introduces some level of invariance to small translations,
A Gentle Introduction to Pooling Layers for Convolutional Neural Networks
D’après AG, maxPooling est meilleur que avgPooling car max Pooling garde les features les plus importants.
MaxPooling and AvgPooling peuvent aussi être utilisés sur la 2ème dimension (profondeur) mais c’est rarement fait.
- How to Develop a CNN for MNIST Handwritten Digit
- MNIST Classification with Eager Execution – Livre Advanced Applied Deep Learning de: Umberto Michelucci
- Aurélien Geron Hands-On Machine Learning – Chapter 14: Deep Computer Vision Using Convolutional Neural Networks
- CNS1-MNIST-Classification.ipynb
Le code est très voisin de celui présenté dans l’exercice Build, compile and train machine learning (ML) models.
import tensorflow as tf
print (tf.__version__)
from tensorflow import keras
# Lecture du dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train.shape[0]
60000
X_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
X_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
A la différence du code cité plus haut, ici on travaille sur des images qui ne sont pas vectorisées mais au contraire on utilise la dimension spatiale en appliquant des convolutions, MaxPool, …
Il est donc nécessaire de faire un reshape de nos matrices (28, 28) pour en faire des tenseurs (28,28,1) + le batch.
from functools import partial
DefaultConv2D = partial(keras.layers.Conv2D, kernel_size=3, activation='relu', padding="SAME")
Pour des facilités d’écriture, on utilise partial de functools.
model = keras.models.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
keras.layers.MaxPooling2D(pool_size=2),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
keras.layers.MaxPooling2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=10, activation='softmax'),
Aurélien Geron recommande d’utilise des kernels 2,3 pour les convolutions et pooling sauf pour la 1ère couche de convolution pour laquelle il dit que (5,5) ou (7,7) offrent un meilleur résultat. Faisons-lui confiance.
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
Nous avons déjà expliqué pourquoi utiliser SparseCategoricalCrossentropy.
Contrairement à un exemple précédent déjà commenté, la fonction n’est pas :
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
Le from_logits=True n’a pas lieu d’être ici car le modèle se termine par un softmax.
keras.layers.Dense(units=10, activation='softmax')
Computes the crossentropy loss between the labels and predictions.
Use this crossentropy loss function when there are two or more label classes. We expect labels to be provided as integers. If you want to provide labels using one-hot representation, please use CategoricalCrossentropy loss.
model.compile(optimizer='adam',loss=loss_fn, metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 64) 3200
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 128) 73856
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 256) 295168
_________________________________________________________________
conv2d_4 (Conv2D) (None, 7, 7, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 2304) 0
_________________________________________________________________
dense (Dense) (None, 128) 295040
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 8256
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 1,413,834
Trainable params: 1,413,834
Non-trainable params: 0
_________________________________________________________________On a tout d’abord 3200 paramètres, ce qui correspond à un kernel de 7 (7*7) auquel on ajoute un biais (49+1=50) et on multiplie par le nombre de filtres (64) ce qui donne 3200 paramètres.
model.fit(X_train, y_train, epochs=5)
Epoch 1/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.3651 - accuracy: 0.8864
Epoch 2/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.1169 - accuracy: 0.9722
Epoch 3/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.0821 - accuracy: 0.9798
Epoch 4/5
1875/1875 [==============================] - 30s 16ms/step - loss: 0.0765 - accuracy: 0.9830
Epoch 5/5
1875/1875 [==============================] - 31s 16ms/step - loss: 0.0626 - accuracy: 0.9856
<tensorflow.python.keras.callbacks.History at 0x7f29f052bba8>