
Le notebook de référence pour ce tutoriel est TimeSeries.
Avant de commencer à étudier RNN et CNN pour les time series, commençons par un modèle linéaire très simple.
Modèle linéaire
Le tutoriel qui sert de référence pour celui-ci est Forecasting de Sequences, Time Series and Prediction (Coursera/Semaine 2) et plus particulièrement le notebook S+P Week 2 Lesson 2.ipynb
Les données sont préparées tel que décrit dans notre article Prepare features and labels
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1]))
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
Ensuite un modèle est créé :
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
print(dataset)
l0 = tf.keras.layers.Dense(1, input_shape=[window_size])
model = tf.keras.models.Sequential([l0])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset,epochs=100,verbose=0)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1) 21
=================================================================
Total params: 21
Trainable params: 21
Non-trainable params: 0
model.fit(dataset,epochs=100,verbose=0)
myweights, mybias=l0.get_weights()
myweights
array([[-0.06807945],
[ 0.00441364],
[ 0.05399206],
[-0.03565589],
[ 0.06098474],
[ 0.06372922],
[-0.10915841],
[ 0.00682205],
[ 0.01581037],
[ 0.04594234],
[-0.08730657],
[ 0.03207239],
[ 0.00571096],
[ 0.02093075],
[-0.04836704],
[ 0.11473672],
[ 0.05038786],
[ 0.16847259],
[ 0.25107303],
[ 0.43803504]], dtype=float32)
mybias
array([0.0149056], dtype=float32)Une fois l’apprentissage effectué, on regarde les prédictions :
forecast = []
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
5.0760803ANN
Pour l’ANN, les données sont créées comme précédemment.
Le modèle est séquentiel.
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=[window_size], activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 210
_________________________________________________________________
dense_1 (Dense) (None, 10) 110
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 331
Trainable params: 331
Non-trainable params: 0
model.fit(dataset,epochs=100,verbose=0)
forecast = []
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
4.61267RNN
RNN a déjà été exploré lors de son utilisation sur le texte. Voir Add RNN and GRU, RNNS, LSTMs, GRUs and CNNs
Un RNN attend 3 dimensions en input : batch size, timestamps, series dimensionality.
Supposons les données précédentes.
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
train_set = windowed_dataset(x_train, window_size, batch_size=128, shuffle_buffer=shuffle_buffer_size)
Le return_sequences=True dans le 1er RNN car on a à la suite un autre RNN qui prend entrée toutes les sorties du précédent RNN
model = tf.keras.models.Sequential([
tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1), input_shape=[None]),
tf.keras.layers.SimpleRNN(40, return_sequences=True),
tf.keras.layers.SimpleRNN(40),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 100.0)
])
On cherche le meilleur lr en testant le RNN sur une centaine d’epochs.
lr_schedule = tf.keras.callbacks.LearningRateScheduler(
lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)
La fonction de perte est Huber, une fonction moins sensible aux outliers.
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lambda (Lambda) (None, None, 1) 0
_________________________________________________________________
simple_rnn (SimpleRNN) (None, None, 40) 1680
_________________________________________________________________
simple_rnn_1 (SimpleRNN) (None, 40) 3240
_________________________________________________________________
dense (Dense) (None, 1) 41
_________________________________________________________________
lambda_1 (Lambda) (None, 1) 0
=================================================================
Total params: 4,961
Trainable params: 4,961
Non-trainable params: 0
history = model.fit(train_set, epochs=100, callbacks=[lr_schedule])
plt.semilogx(history.history["lr"], history.history["loss"])
plt.axis([1e-8, 1e-4, 0, 30])
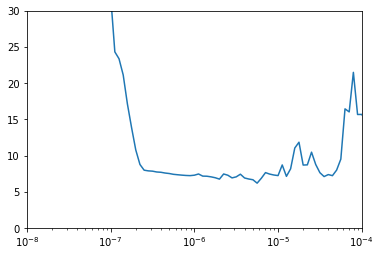
On recommence avec le nouveau lr : 5e-5 puisque c’est entre e-6 et e-5 que ça dégénère.
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
dataset = windowed_dataset(x_train, window_size, batch_size=128, shuffle_buffer=shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1),
input_shape=[None]),
tf.keras.layers.SimpleRNN(40, return_sequences=True),
tf.keras.layers.SimpleRNN(40),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 100.0)
])
optimizer = tf.keras.optimizers.SGD(lr=5e-5, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(dataset,epochs=400)
forecast=[]
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
6.6527605LSTM
LSTM a déjà été décrit dans un autre article dans un cas d’utilisation de NLP : Train LSTMs et LSTMs.
Supposons encore une fois les mêmes données :
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
dataset = windowed_dataset(x_train, window_size, batch_size=128, shuffle_buffer=shuffle_buffer_size)
On met 2 LSTM à la suite (return_sequence=True) et ils sont bidirectionnels.
model = tf.keras.models.Sequential([
tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1), input_shape=[None]),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 100.0)
])
Cette fois loss=MSE mais ça ne change rien.
model.compile(loss="mse",
optimizer=optimizer,
metrics=["mae"])
model.fit(dataset,epochs=100,verbose=1)
Le résultat est MAE: 4.8631, ce qui est très bon