Ce tutoriel de classification d’iris, à l’aide de TensorFlow 2.x est le suivant du … #1 et du #2 au cours duquel nous avons étudié la création du dataset et du modèle. Tout ce qui est écrit en #1 et #2 est donc supposé être connu.
On poursuit avec la boucle d’apprentissage.
Le problème
Classer des iris, en 3 catégories (Iris setosa, Iris virginica et Iris versicolor), à partir des dimensions (largeur et longueur) des sépales et pétales est un problème classique du Machine Learning. Puisqu’on peut le traiter facilement avec les outils de la statistique, pourquoi ne pas essayer de le faire, de façon plus compliquée avec un réseau de neurones ! Tout cela, bien sûr, dans un but pédagogique.

Références
- Custom training: walkthrough
- Premade Estimators
- TensorFlow – tutoriel #1
- Tutorial Classification
- Scatter Matrices using pandas
- How to use Pandas Scatter Matrix
- Dataset 5 fleurs
- How does the Softmax activation function work?
- TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
- Get started with TensorBoard
Code
Le notebook Jupyter, en Python, dans l’environnement GCP est disponible ici.
Gist
Boucle d’apprentissage
Intéressons-nous uniquement à ce qui est fondamental dans la boucle. Le reste ne sert qu’à l’enregistrement et à l’affichage des résultats.
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
La boucle externe itère sur le nombre d’epochs, c’est le nombre de fois que l’on va parcourir l’ensemble du jeu de données
La boucle interne itère sur le dataset. Pour chaque élément, on calcule la sortie du réseau, la perte (forward du réseau), le gradient et on met à jour les poids.
Si on utilise fit, c’est beaucoup plus simple, tout se fait automatiquement.
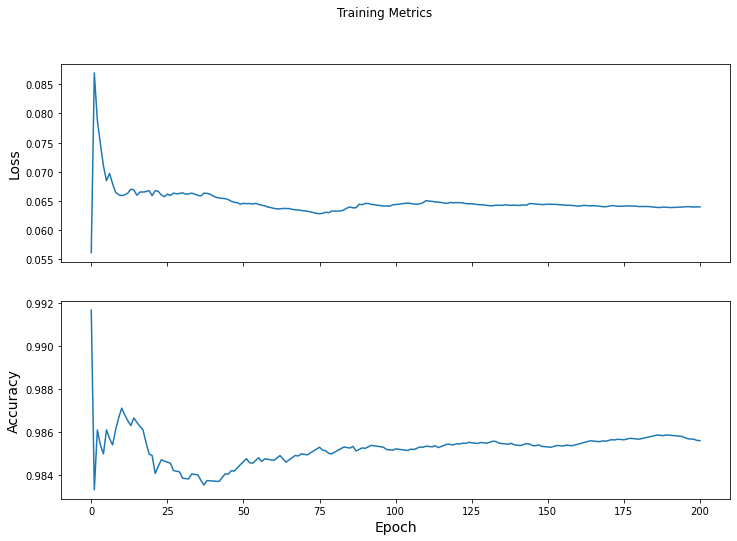
Visualisation des résultats
Pour afficher l’évolution de la perte et de l’accuracy dans le temps, selon les epochs :
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
Les courbes obtenues sont celles-ci :
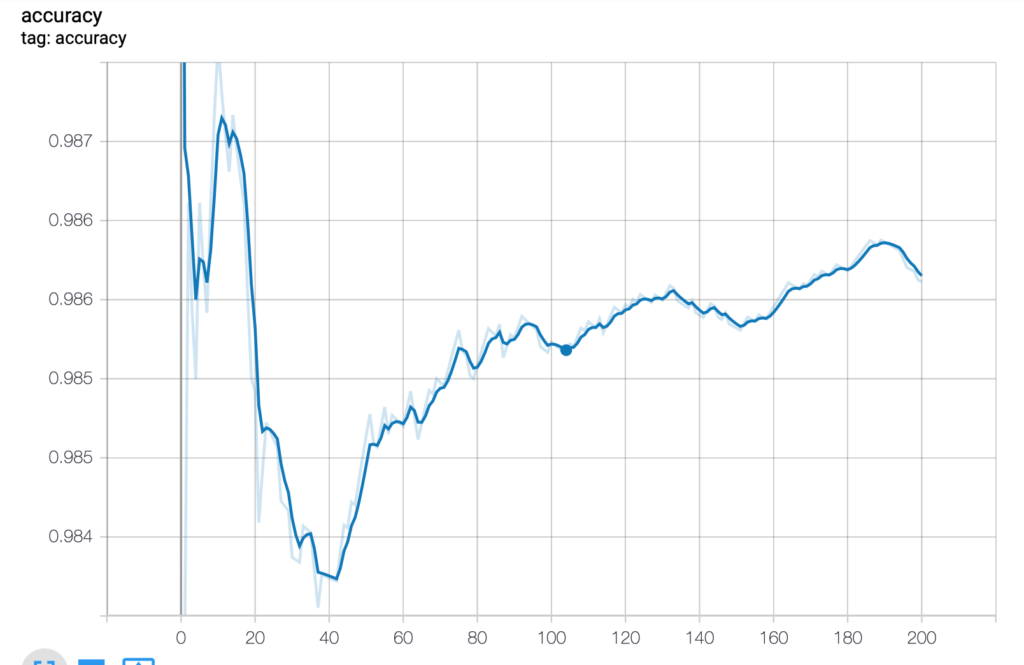
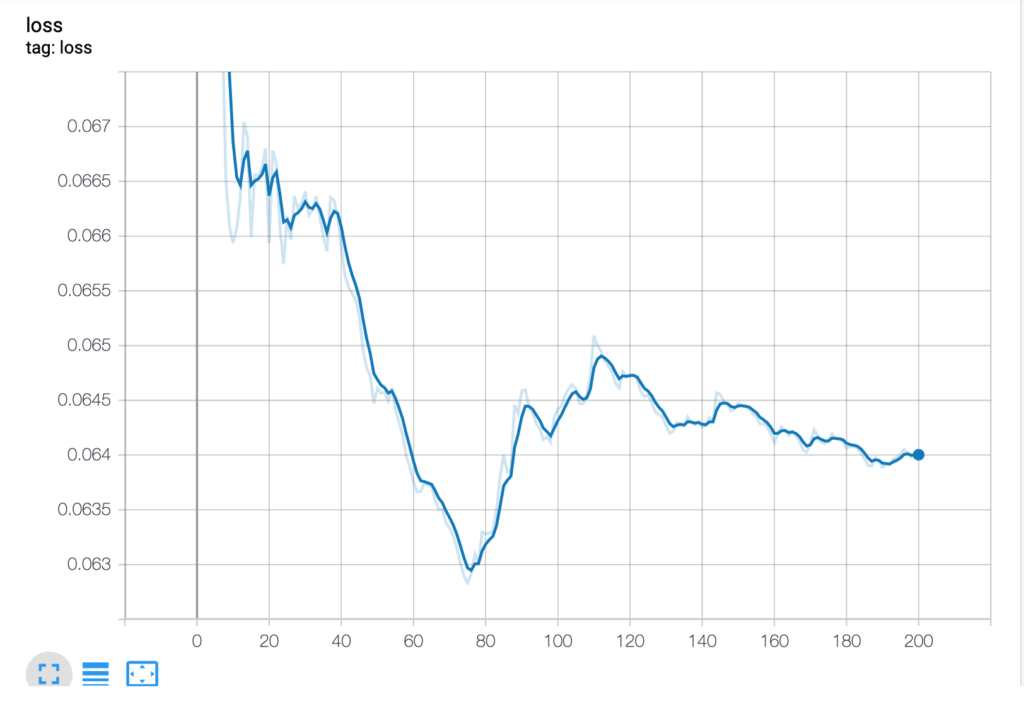
On peut aussi choisir d’utiliser l’outil TensorBoard pour mémoriser et afficher les résultats.
Avec TensorBoard
Ce n’est pas dans le code d’origine, il a été ajouté par nous en s’inspirant de Get started with TensorBoard.
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runs
!rm -rf ./logs/
import datetime
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
train_loss.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
train_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(train_loss.result())
train_accuracy_results.append(train_accuracy.result())
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
train_loss.result(),
train_accuracy.result()))
%tensorboard --logdir logs/gradient_tape