
Le tutoriel qui sert de référence pour ici est Deep neural network de Sequences, Time Series and Prediction (Coursera/Semaine 2) et plus particulièrement le notebook S+P Week 2 Lesson 3.ipynb
Le tutoriel Use RNNs and CNNs sur ce site explique comment préparer le jeu de données, comment effectuer un apprentissage.
L’hyperparamètre probablement le plus important à « tuner » est le learning rate.
Pour cela il existe différentes méthodes, notamment grid search.
On peut aussi le faire de la manière décrite par Jeremy Howard, voisine de celle proposée ici.
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=[window_size], activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
lr_schedule = tf.keras.callbacks.LearningRateScheduler(
lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)
model.compile(loss="mse", optimizer=optimizer)
history = model.fit(dataset, epochs=100, callbacks=[lr_schedule], verbose=0)
Lors du fit, on a un callback à chaque epoch sur le calcul du nouveau learning rate.
On effectue une centaine d’epochs.
On fait un plot du lr vs loss
lrs = 1e-8 * (10 ** (np.arange(100) / 20))
plt.semilogx(lrs, history.history["loss"])
plt.axis([1e-8, 1e-3, 0, 300])
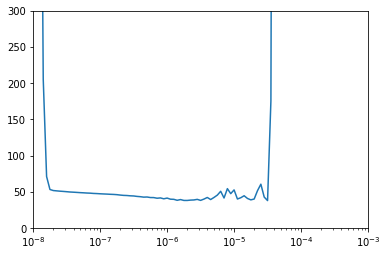
On regarde à quel moment la perte cesse de décroître.
On refit avec le nouveau lr.
taset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size) model = tf.keras.models.Sequential([ tf.keras.layers.Dense(10, activation="relu", input_shape=[window_size]), tf.keras.layers.Dense(10, activation="relu"), tf.keras.layers.Dense(1)]) optimizer = tf.keras.optimizers.SGD(lr=8e-6, momentum=0.9)model.compile(loss="mse", optimizer=optimizer)history = model.fit(dataset, epochs=500, verbose=0)