
Difficile de savoir ce qui est attendu par TensorFlow pour ce 1er skill en Time Series.
On peut supposer qu’il s’agit d’utiliser des réseaux de neurones pour du forecast. On peut aussi penser qu’il s’agit d’une introduction aux Time Series.
Le tutoriel qui sert de référence pour celui-ci est Forecasting de Sequences, Time Series and Prediction (Coursera/Semaine 1).
Naive forecast
Supposons, la série de données x_valid :
split_time = 1000
x_valid = series[split_time:]
naive_forecast = series[split_time - 1:-1]
naive_forecast[0], naive_forecast[1], naive_forecast[2]
(67.19674, 71.34472, 68.98551)
x_valid[0], x_valid[1], x_valid[2]
(71.34472, 68.98551, 64.6752)
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid, start=0, end=150)
plot_series(time_valid, naive_forecast, start=1, end=151)
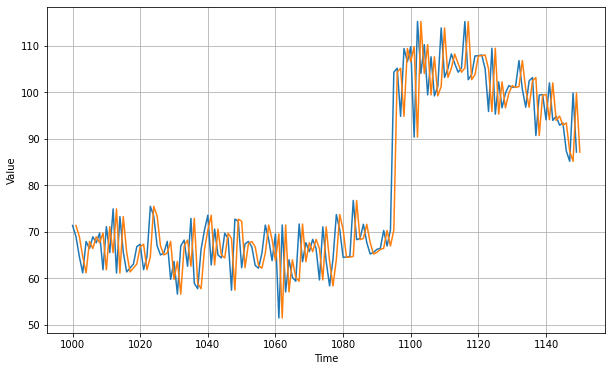
Pour mesurer la pertinence de la prévision on utilise MSE ou MAE
print(keras.metrics.mean_squared_error(x_valid, naive_forecast).numpy())print(keras.metrics.mean_absolute_error(x_valid, naive_forecast).numpy())
61.827538
5.937908Moving average:
def moving_average_forecast(series, window_size):
"""Forecasts the mean of the last few values.
If window_size=1, then this is equivalent to naive forecast"""
forecast = []
for time in range(len(series) - window_size):
forecast.append(series[time:time + window_size].mean())
return np.array(forecast)
moving_avg = moving_average_forecast(series, 30)[split_time - 30:]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, moving_avg)
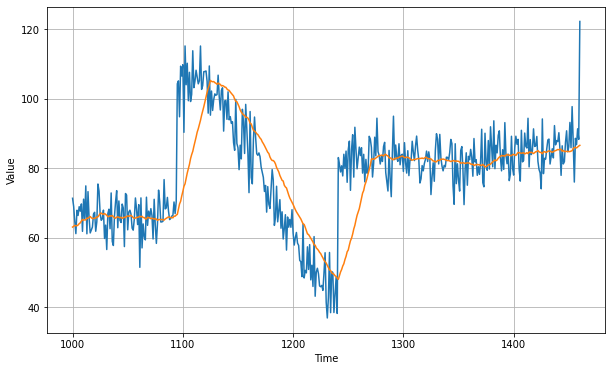
print(keras.metrics.mean_squared_error(x_valid, moving_avg).numpy())
print(keras.metrics.mean_absolute_error(x_valid, moving_avg).numpy())
106.674576
7.142419Les résultats ne sont pas terribles !
differencing
On effectue d’abord le delta entre les données des périodes.
diff_series = (series[365:] - series[:-365])
diff_time = time[365:]
Puis ensuite on effectue un moving average
diff_moving_avg = moving_average_forecast(diff_series, 50)[split_time - 365 - 50:]
et on rajoute les données de la période précédente
diff_moving_avg_plus_past = series[split_time - 365:-365] + diff_moving_avg
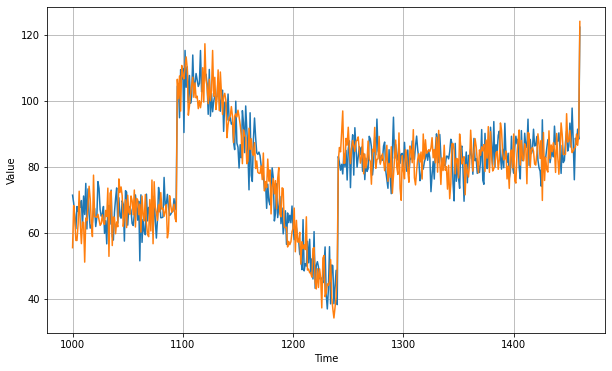
print(keras.metrics.mean_squared_error(x_valid, diff_moving_avg_plus_past).numpy())print(keras.metrics.mean_absolute_error(x_valid, diff_moving_avg_plus_past).numpy())
52.97366
5.839311Les résultats sont meilleurs cette fois.